Source text: A Review of Machine Learning
The Learning Machines
Interest in machine learning has exploded over the past decade. You see machine learning in computer science programs, industry conferences, and the Wall Street Journal almost daily. For all the talk about machine learning, many conflate what it can do with what they wish it could do. Fundamentally, machine learning is using algorithms to extract information from raw data and represent it in some type of model. We use this model to infer things about other data we have not yet modeled.
Translation:
Des machines qui apprennent
Ces dix dernières années, l’apprentissage automatique ou « machine learning » est devenu un sujet incontournable. Le machine learning s’invite dans les programmes informatiques, les conférences du secteur de l’industrie et même dans le quotidien américain The Wall Street Journal presque tous les jours. Aujourd’hui, le terme machine learning est sur toutes les lèvres, pour autant, beaucoup s’en font une image différente de la réalité. La fonction essentielle du machine learning est d’obtenir des informations à partir de données brutes à l’aide d’algorithmes, puis d’en créer un « modèle ». Grâce à ce modèle, on peut arriver à des conclusions concernant d’autres données qui n’ont pas encore été modélisées.
ST: Neural networks are one type of model for machine learning ; they have been around for at least 50 years. The fundamental unit of a neural network is a node, which is loosely based on the biological neuron in the mammalian brain. The connections between neurons are also modeled on biological brains, as is the way these connections develop over time (with “training”). We’ll dig deeper into how these models work over the next two chapters.
Tr: Les réseaux de neurones constituent l’un des modèles du machine learning, utilisé depuis plus de 50 ans. L’unité fondamentale d’un réseau de neurones artificiels est le « nœud », qui fonctionne comme un neurone biologique dans le cerveau des mammifères. Les connexions entre neurones artificiels sont également construites comme celles des cerveaux biologiques, et il en est de même pour la façon dont ces connexions se développent avec le temps (par « apprentissage »). Nous étudierons le mode de fonctionnement de ces modèles de façon plus approfondie dans les deux prochains chapitres.
ST: In the mid-1980s and early 1990s, many important architectural advancements were made in neural networks. However, the amount of time and data needed to get good results slowed adoption, and thus interest cooled. In the early 2000s computational power expanded exponentially and the industry saw a “Cambrian explosion” of computational techniques that were not possible prior to this. Deep learning emerged from that decade’s explosive computational growth as a serious contender in the field, winning many important machine learning competitions. The interest has not cooled as of 2017; today, we see deep learning mentioned in every corner of machine learning.
Tr: Au milieu des années 1980 – début 1990, de grandes avancées dans les architectures des réseaux de neurones ont été réalisées. Cependant, en raison du temps et de la quantité considérable de données nécessaires, l’adoption de ces technologies a été ralentie puis l’intérêt s’est estompé. Au début des années 2000, la puissance de calcul des machines a explosé de manière exponentielle. On peut parler à cette époque d’« explosion cambrienne » dans les techniques de calcul de l’industrie informatique, surpassant les possibilités jusqu’alors existantes. De cette décennie de croissance incroyable des moyens de calculs, émergea le deep learning, ou apprentissage profond, sérieux concurrent dans le domaine du machine learning qui remportera de nombreuses compétitions. À ce jour en 2017, l’intérêt pour le deep learning n’a pas faibli. Bien au contraire, il est cité aujourd’hui à chaque évocation du machine learning.
ST: We’ll discuss our definition of deep learning in more depth in the section that follows.
This book is structured such that you, the practitioner, can pick it up off the shelf and do the following:
- Review the relevant basic parts of linear algebra and machine learning
- Review the basics of neural networks
- Study the four major architectures of deep networks
- Use the examples in the book to try out variations of practical deep networks
Tr: Nous développerons de manière détaillée notre définition du deep learning dans la section suivante.
Cet ouvrage est structuré de façon à ce que vous, en tant que professionnel, puissiez facilement :
- Revoir les éléments pertinents de l’algèbre linéaire et du machine learning
- Revenir sur les rudiments des réseaux de neurones
- Étudier les quatre principales architectures des réseaux profonds (deep networks)
- Utiliser les exemples présentés pour tester les variantes de réseaux profonds existants.
ST: We hope that you will find the material practical and approachable. Let’s kick off the book with a quick primer on what machine learning is about and some of the core concepts you will need to better understand the rest of the book.
Tr: Nous espérons que vous trouverez son contenu utile et abordable. Commençons par une rapide introduction sur le machine learning et quelques concepts essentiels que vous devrez maîtriser afin de poursuivre plus avant dans l’ouvrage.
ST: Fundamentals of Deep Networks
Defining Deep Learning
In the Chapter 2 we set up the foundations of machine learning and neural networks.
In this chapter we’ll build on these foundations to give you the core concepts of deep networks. This will help build your understanding of what is going on in different network architectures as we progress into the specific architectures in Chapter 4 and then the practical examples in Chapter 5. Let’s begin by restating our definitions of both deep learning and deep networks.
Tr: Les bases des réseaux profonds
Définition du Deep Learning
Dans le chapitre 2, nous avons établi les fondements du machine learning et des réseaux de neurones. Dans ce chapitre, nous allons tirer parti de ces fondements afin d’appréhender les concepts de base des réseaux profonds. Vous comprendrez ainsi plus facilement les tenants et aboutissants des différentes architectures de réseaux, avant de passer aux architectures spécifiques dans le chapitre 4 et aux exemples concrets du chapitre 5. Commençons par un rappel des définitions du deep learning et des réseaux profonds.
ST: What Is Deep Learning?
Revisiting our definition of deep learning from Chapter 1, the facets that differentiate deep learning networks in general from “canonical” feed-forward multilayer networks are as follows:
- More neurons than previous networks
- More complex ways of connecting layers
- “Cambrian explosion” of computing power to train
- Automatic feature extraction
Tr: Qu’est-ce que le Deep Learning ?
Revenons sur notre définition du deep learning du premier chapitre de cet ouvrage. Les réseaux multi-couches à rétro-propagation se distinguent des réseaux habituels du deep learning par :
- Un plus grand nombre de neurones que les réseaux précédents
- Des connexions plus complexes entre les couches
- Une extraordinaire explosion de la puissance de calcul pour l’entraînement des machines
- La reconnaissance automatique de caractéristiques
ST: When we say “more neurons,” we mean that the neuron count has risen over the years to express more complex models. Layers also have evolved from each layer being fully connected in multilayer networks to locally connected patches of neurons between layers in Convolutional Neural Networks (CNNs) and recurrent connections to the same neuron in Recurrent Neural Networks (in addition to the connections from the previous layer).
Tr: Ce que nous entendons par « un plus grand nombre de neurones », c’est des modèles qui au fil des années, sont devenus de plus en plus complexes. Autre évolution importante, celle des couches qui composent les réseaux de neurones. Initialement, chaque couche était connectée à l’ensemble des autres couches dans les réseaux multi-couches. Aujourd’hui, dans les Réseaux de Neurones Convolutifs, ou RNC (Convolutional Neural Networks), des grappes de neurones locales sont connectées entre les couches et dans les Réseaux de Neurones Récurrents, ou RNR (Recurrent Neural Networks), un même neurone reçoit des connexions répétées (en plus des connexions provenant de la couche précédente).
ST: More connections means that our networks have more parameters to optimize, and this required the explosion in computing power that occurred over the past 20 years. All of these advances provided the foundation to build next-generation neural networks capable of extracting features for themselves in a more intelligent fashion. This allowed deep networks to model more complex problem spaces (e.g., image recognition advances) than previously possible. As industry demands are ever changing and ever reaching, the capabilities of neural networks have had to charge forward. The Red Queen would have it no other way.
Tr: Plus de connexions signifie plus de paramètres à optimiser pour nos réseaux, ce qui a été permis par l’explosion des capacités informatiques de ces 20 dernières années. Toutes ces avancées ont fourni les bases permettant de construire des réseaux de neurones nouvelle génération, capables d’effectuer par eux-mêmes de la reconnaissance de caractéristiques de manière plus intelligente. Les réseaux profonds ont ainsi pu modéliser davantage d’espaces-problèmes complexes (par ex. progrès dans la reconnaissance d’image). La demande du secteur industriel étant en constante évolution et de plus en plus ambitieuse, il a fallu aller plus loin dans les capacités des réseaux de neurones.
ST: Defining deep networks
To further provide color to our definition of deep learning, here we define the four major architectures of deep networks:
- Unsupervised Pretrained Networks
- Convolutional Neural Networks
- Recurrent Neural Networks
- Recursive Neural Networks
Tr: Définition des réseaux profonds
Avançons dans notre définition du deep learning avec la description des quatre principales architectures des réseaux profonds :
- Réseaux pré-entraînés non supervisés
- Réseaux de Neurones Convolutifs
- Réseaux de Neurones Récurrents
- Réseaux de Neurones Récursifs
ST: There is continuous research in the domain of neural networks, but for the purposes of this book, we’ll focus on these four architectures. These architectures have evolved over the past 20 years. Let’s take a quick look at some of the highlights, continuing our history lesson that began in Chapter 1 on the history of feed-forward multilayer neural networks.
Tr: Les recherches sont constantes dans le domaine des réseaux de neurones, mais pour les besoins de cet ouvrage, nous allons nous concentrer sur ces quatre architectures qui ont beaucoup évolué ces 20 dernières années. Poursuivons à présent l’histoire des réseaux de neurones multi-couches à rétro-propagation commencée dans le chapitre 1, en examinant rapidement quelques faits marquants.
ST: Deep Reinforcement Learning
Reinforcement learning is defined in Sutton’s book as follows:
Reinforcement learning is defined not by characterizing learning methods, but by characterizing a learning problem.
It goes on to state that any method suitable to solving that problem can be considered to be a reinforcement learning method. In reinforcement learning, we do not tell the learner which actions to take, but let the agent discover the actions yielding the best reward by experimenting in a simulation.
Tr: Apprentissage profond par renforcement
L’apprentissage par renforcement est défini comme suit dans le livre de Richard S. Sutton (Reinforcement Learning, An Introduction, Éditions Bradford, 1998) :
L’apprentissage par renforcement se définit non pas par la caractérisation de méthodes d’apprentissage mais par la caractérisation d’une problématique d’apprentissage.
Il continue en affirmant que toute méthode susceptible de résoudre un problème en particulier peut être considérée comme de l’apprentissage par renforcement. Dans ce cadre, l’apprenant n’est pas guidé dans le choix des actions, mais l’agent logiciel en question découvre par lui-même, par l’expérimentation au cours de simulations, quelles actions apportent la meilleure récompense.
ST: In reinforcement learning, the agent begins with no trained model of the environment, and the utility function is synonymous with the reward or objective our agent is after. The training system gives the agent input from the environment and rewards the agent when the outcome (of the cycle, or frame) of the simulation (or game) being played is positive. Many times, actions will affect not only the immediate reward, but also future rewards. The mechanics of trial-and-error and delayed reward are key features of reinforcement learning.
Tr: Dans l’apprentissage par renforcement, l’agent part d’un environnement dont le modèle n’est pas « entraîné » et la fonction utilitaire dépend de la récompense ou de l’objectif recherché(e). Le système d’entraînement fournit les données d’entrée de l’environnement à l’agent et le récompense lorsque le résultat de la simulation effectuée (ou confrontation) est positif. L’apprentissage par renforcement utilise principalement les mécanismes de recherche par tâtonnement ou de récompense différée, car souvent, les actions influencent autant la récompense directe que celles à venir.
ST: Deep reinforcement learning is a variant of reinforcement learning in which a neural network is used as the universal function’s approximator. The drawback to this approach is that the behavior of a neural network is not bounded, and the proof of convergence doesn’t hold anymore. However, using neural networks as the universal function approximator shows good results despite this.
Tr: L’apprentissage profond par renforcement est une variante de l’apprentissage par renforcement, qui utilise un réseau de neurones comme approximateur de fonction universel. Le désavantage de cette méthode réside dans le fait qu’un réseau de neurones n’a pas un comportement délimité, et que la preuve de convergence (de l’algorithme) devient caduque. Pour autant, l’utilisation de réseaux de neurones en tant qu’approximateur de fonction universel montre de bons résultats.
ST: In 2013 a paper was published by the DeepMind team at the NIPS 2013 Deep Learning Workshop on playing ATARI games with Deep Q Learning. In this paper, the authors used a standard algorithm (Q Learning with function approximation). Their function approximator for this algorithm was a CNN. They demonstrated an agent playing Atari 2600 games based on using the pixels on the screen as input and a CNN as the internal model.
Tr: Un article a été publié en 2013 par l’équipe DeepMind qui était présente lors de la conférence scientifique en intelligence artificielle et neurosciences computationnelles NIPS 2013 (Neural Information Processing Systems), au sujet de l’utilisation du Deep Q-Learning (algorithme Deep Q-Network) dans les jeux ATARI. Dans cet article, les auteurs utilisèrent un algorithme standard, Q-Learning avec approximation de fonction, dont l’approximateur était un RNC. La démonstration portait sur un agent capable de jouer à des jeux Atari 2600 en utilisant les pixels affichés à l’écran comme données d’entrée et un RNC comme modèle interne.
ST: The computer/agent playing the ATARI game was positively rewarded when the outcome of the game was positive based on the actions performed. The algorithm was able to learn some of the games to a level where it performed better than humans.
Tr: Cet agent logiciel était récompensé lorsque le résultat du jeu était positif suite aux actions réalisées. L’algorithme était capable d’apprendre suffisamment du jeu pour y surpasser les humains.
ST: Deep reinforcement learning has risen in popularity over the course of production of this book, and hopefully we’ll see it included in a future edition. For now we’ll direct you to an example in Appendix B.
Tr: L’apprentissage profond par renforcement a gagné en popularité alors que cet ouvrage n’était pas encore produit, nous espérons donc l’inclure davantage dans une prochaine édition. Pour le moment, rendez-vous à l’exemple en annexe B.
ST: Evolutionary progress and resurgence
When we last left off in Chapter 2, neural networks had entered a “winter period” in the mid-1980s when the promise of AI fell short of what it could deliver. As happens many times when promising technology falls into the Trough of Disillusionment (Figure 2-1), there were many researchers still doing important work in the realm of neural networks.
Tr: Progrès évolutif et résurgence
Nous nous étions arrêtés au chapitre 2 sur les années 1980, lorsque les réseaux de neurones et l’Intelligence Artificielle (IA) ont failli au progrès et aux avancées espérés, les plongeant dans une période creuse. Comme souvent lorsqu’une technologie prometteuse tombe dans le « Gouffre des désillusions » (voir graphique 2-1), de nombreux chercheurs continuèrent à travailler dans le domaine des réseaux de neurones.
ST: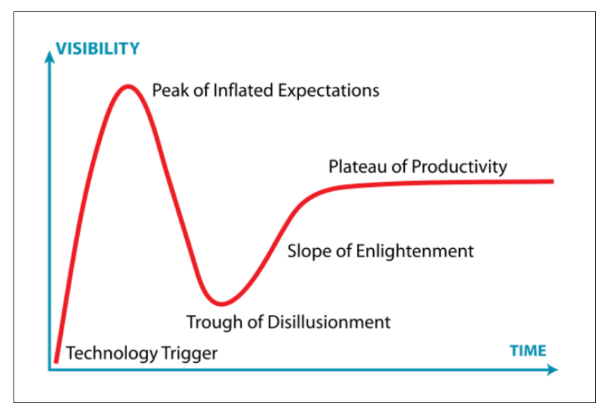
Figure 2-1. Trough of Disillusionment (source: https://en.wikipedia.org/wiki/Hype_cycle)
- Visibility
- TIME
- Peak of Inflated Expectations
- Plateau of Productivity
- Slope of Enlightenment
- Trough of Disillusionment
- Technology Trigger
Tr: Graphique 2-1, Gouffre des désillusions (source : https://fr.wikipedia.org/wiki/Cycle_du_hype)
- VISIBILITÉ
- TEMPS
- Pics des attentes exagérées
- Plateau de productivité
- Pente de l’illumination
- Gouffre des désillusions
- Lancement de la technologie
ST: One important development in neural networks was Yann LeCun’s work at AT&T Bell Labs on optical character recognition. His lab was focused on check image recognition for the financial services sector. Through this work, LeCun and his team developed the concept of the biologically inspired model of image recognition we know today as CNN. This eventually led to the creation of the MNIST handwriting benchmark (we cover this more later in the chapter) and a progressive number of record accuracy marks achieved by deep learning.
Tr: Le travail de Yann Le Cun aux Laboratoires Bell (ex AT&T Bell Labs) sur la reconnaissance optique de caractères a permis de grandes avancées dans le domaine des réseaux de neurones. Son laboratoire était spécialisé dans la lecture optique de chèques pour le secteur des services financiers. À travers ces recherches, Y. Le Cun et son équipe développèrent un nouveau concept connu aujourd’hui sous le nom de RNC : un modèle de reconnaissance d’image inspiré du modèle biologique. Finalement, ceci aboutit à la création du standard MNIST (« Institut national des normes et de la technologie ») d’écriture manuscrite, et à la progression du nombre de reconnaissances réussies grâce au deep learning.
ST: Better Labeled Data
Another contributing factor to the evolution and success of deep networks was the creation of better and larger labeled datasets such as MNIST and ImageNet.
Advances in modeling sequential data with recurrent neural networks appeared in the late-1980s and early 1990s by researchers such as Sepp Hochreiter. As time went on, the research community created better artificial neuron variants (e.g., Long Short-Term Memory [LSTM] Memory Cell and Memory Cell with Forget Gate) over the course of the late 1990s. The stage for a neural network resurgence was being set quietly in research labs around the world.
Tr: Une meilleure catégorisation des données
La création de plus grands ensembles de données catégorisés, et de meilleure qualité, comme MNIST et ImageNet, a fortement contribué au développement et au succès des réseaux profonds.
Les avancées dans la modélisation de données séquentielles avec des réseaux de neurones récurrents sont apparues grâce à des chercheurs comme Sepp Hochreiter, à la fin des années 1980 – début des années 1990. Au cours de la fin des années 90, la communauté de chercheurs créa de meilleures variantes de neurones artificiels, comme par exemple les Long Short-Term Memory (LSTM, c-à-d à mémoire court et long terme), la Cellule de Mémoire et Cellule de Mémoire avec Porte d’Oubli (Memory Cell with Forget Gate). Les laboratoires de recherche du monde entier ont donc patiemment préparé le retour des réseaux de neurones sur le devant de la scène.
ST: During the 2000s, researchers and industry applications began to progressively apply these advances in products such as the following:
- Self-driving cars
- Google Translate
- Amazon Echo
- AlphaGo
Self-driving cars in the 2006 Darpa Grand Challenge used many techniques beyond just deep learning. The top teams (Stanford and Carnegie Mellon University) were able to take advantage of the big improvements of image processing.
Tr: Pendant les années 2000, ces avancées ont progressivement trouvé des applications dans l’industrie avec des produits comme :
- Véhicules autonomes
- Google Traduction
- Amazon Echo
- AlphaGo
Au DARPA Grand Challenge de 2006 (compétition organisée par la DARPA), les véhicules autonomes utilisèrent de nombreuses techniques au-delà du seul deep learning. Les meilleures équipes sont celles qui ont réussi à intégrer les énormes progrès dans le traitement d’image : Stanford et l’Université Carnegie-Mellon aux États-Unis.
ST: Advances in Computer Vision
In 2012 Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton developed a “large, deep convolutional neural network” that won the 2012 ILSVRC (ImageNet Large-Scale Visual Recognition Challenge).
AlexNet was hailed as an advancement in computer vision and some credit it specifically with kicking off the deep learning craze. However, it was largely a scaled-up (e.g., deeper and wider) variant of the CNNs from the 1990s. The recent advances in computer vision were driven less by recent algorithm advances and more by better compute, data, and infrastructure.
Tr: Innovations dans la Vision par Ordinateur
En 2012, Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton développèrent un réseau de neurones convolutif profond de grande ampleur qui remporta la Compétition ImageNet de Reconnaissance Visuelle à Grande Échelle (ILSVRC).
L’algorithme AlexNet a été salué en tant qu’avancée dans la vision par ordinateur ou artificielle. Certains le considèrent même comme étant à l’origine de l’engouement pour le deep learning. Cependant, il n’était qu’une variante à plus grande échelle du RNC des années 90. Les derniers progrès dans la vision par ordinateur sont plus liés à de meilleurs traitements, de meilleures données et de meilleures infrastructures qu’aux récents progrès des algorithmes.
ST: Better image analysis allowed the planning systems in the cars to better choose paths through uncertain terrain and avoid obstacles more safely. Other advances in deep learning allowed models to more accurately translate and recognize audio data, driving value in the Google Translate and Amazon Echo line of products. Most recently, we’ve seen another complex game fall at the master level when the AlphaGo system beat the 9-dan professional Go player Lee Sedol.
Tr: Le progrès dans l’analyse d’images a permis aux systèmes de gestion des véhicules de choisir des trajectoires plus sûres en évaluant la nature du terrain et en évitant les obstacles. D’autres innovations du deep learning ont permis aux modèles de traduire et reconnaître des données audio de façon plus fidèle, ce qui créa de la valeur ajoutée pour les lignes de produits Google Traduction et Amazon Echo. Plus récemment, on a à nouveau assisté à un échec au jeu niveau « master », lorsque le programme AlphaGo a battu le joueur professionnel Lee Sedol (9e dan) au jeu de go.
ST: Big advances in what machine learning can accomplish are not always easy to see. Public recognition for these advances many times is the culmination of many different lines of work that is exhibited in high-profile demonstrations such as The Darpa Grand Challenge or Watson beating Ken Jennings in Jeopardy. However, behind the scenes, the underpinnings for these advances change slowly but constantly. Just like the changing of the seasons, we don’t always notice these changes in our daily lives until they’ve crossed some threshold.
Tr: Les grandes avancées dans les applications du machine learning sont parfois obscures. Leur reconnaissance publique est souvent l’aboutissement de nombreux axes de travail différents, présentés à l’occasion de démonstrations réputées comme le Darpa Grand Challenge ou lors de la défaite de Ken Jennings au Jeopardy face à Watson (programme informatique d’IA) en 2011. Cependant, les fondements à la base de ces progrès évoluent lentement mais sûrement, à l’abri des regards, tout comme les changements de saison que l’on ne remarque que lorsqu’une certaine étape est franchie.
ST: In the near future, we’ll continue to see deep learning being applied in unique and innovative ways. This application will be more of the latent intelligence variety (e.g., recommendations or voice recognition) coupled with pragmatic engineering to make them useful in everyday aspects of our lives. What we’re unlikely to see (in the near term, at least) are out of control malevolent artificial agents blowing us out of airlocks at inopportune times (think HAL 9000 from 2001: A Space Odyssey).
Tr: Il ne fait aucun doute que le deep learning livrera encore prochainement des applications exceptionnelles et innovantes. Les utilisations reposeront en fait sur la variété des intelligences disponibles (par ex. recommandations ou reconnaissance vocale) associées à une conception pragmatique qui les rendront utiles dans notre vie de tous les jours. Ce qui est peu probable, néanmoins dans un avenir proche, c’est de voir des agents intelligents malveillants hors de contrôle nous expulser dans l’espace à travers un sas au mauvais moment (comme HAL 9000 dans 2001, l’Odysée de l’espace).
ST: HAL 9000
HAL 9000 is the fictional computer who controls the systems of the Discovery One spaceship in Arthur C. Clarke’s book 2001: A Space Odyssey. HAL stands for Heuristically programmed ALgorithmic computer. HAL is represented largely in the film as a camera lens with a glowing red dot and is accessed through a conversational voice recognition system. In the film, HAL concludes that it must kill off the crew of the Discovery One to complete its mission successfully.
Dave: Open the pod bay doors, HAL.
HAL: I’m sorry, Dave. I’m afraid I can’t do that.
Tr: HAL 9000
HAL 9000 est l’ordinateur de bord qui commande les fonctions du vaisseau Discovery One dans le livre 2001, l’Odysée de l’espace, d’Arthur C. Clarke. HAL est l’acronyme de « Heuristically programmed ALgorithmic computer » ou « ordinateur algorithmique programmé heuristiquement ». HAL apparaît dans le film principalement sous la forme d’un objectif dont le centre est d’un rouge très lumineux, avec lequel l’équipage interagit grâce à un système de reconnaissance vocale. Dans le film, HAL arrive à la conclusion qu’il doit tuer les membres de l’équipage du Discovery One afin de remplir sa mission.
Dave : Ouvre les portes du hangar, HAL.
HAL : Je suis désolé Dave, je crains de ne pas pouvoir faire ça.
ST: Deep learning continues to push the field forward in many domains and on many core machine learning problems. Here are just a few of the benchmark records deep learning has achieved in the last few years:
- Text-to-speech synthesis (Fan et al., Microsoft, Interspeech 2014)
- Language identification (Gonzalez-Dominguez et al., Google, Interspeech 2014)
- Large vocabulary speech recognition (Sak et al., Google, Interspeech 2014)
- Prosody contour prediction (Fernandez et al., IBM, Interspeech 2014)
- Medium vocabulary speech recognition (Geiger et al., Interspeech 2014)
- English-to-French translation (Sutskever et al., Google, NIPS 2014)
- Audio onset detection (Marchi et al., ICASSP 2014)
- Social signal classification (Brueckner & Schulter, ICASSP 2014)
- Arabic handwriting recognition (Bluche et al., DAS 2014)
- TIMIT phoneme recognition (Graves et al., ICASSP 2013)
- Optical character recognition (Breuel et al., ICDAR 2013)
- Image caption generation (Vinyals et al., Google, 2014)
- Video-to-textual description (Donahue et al., 2014)
- Syntactic parsing for natural language processing (Vinyals et al., Google, 2014)
- Photo-real talking heads (Soong and Wang, Microsoft, 2014)
Tr: Le deep learning fait encore progresser la discipline dans de nombreux domaines et problématiques essentielles du machine learning. Voici par exemple quelques réalisations notoires permises par le deep learning ces dernières années :
- Synthèse texte vers parole (Fan et al., Microsoft, conférence Interspeech 2014)
- Identification de langue (Gonzalez-Dominguez et al., Google, conférence Interspeech 2014)
- Reconnaissance de la parole à vocabulaire étendu (Sak et al., Google, conférence Interspeech 2014)
- Prédiction de contours prosodiques (Fernandez et al., IBM, conférence Interspeech 2014)
- Reconnaissance de la parole à vocabulaire moyen (Geiger et al., conférence Interspeech 2014)
- Traduction de l’anglais vers le français (Sutskever et al., Google, conférence NIPS 2014)
- Reconnaissance de notes de musique (Marchi et al., conférence ICASSP 2014)
- Classification des signaux sociaux (Brueckner & Schulter, conférence ICASSP 2014)
- Reconnaissance de l’écriture arabe (Bluche et al., conférence DAS 2014)
- Reconnaissance de phonèmes de la base de données TIMIT (Graves et al., conférence ICASSP 2013)
- Reconnaissance optique de caractères (Breuel et al., conférence ICDAR 2013)
- Génération de légendes d’images (Vinyals et al., Google, 2014)
- Description textuelle de vidéo (Donahue et al., 2014)
- Analyse syntaxique pour le traitement du langage naturel (Vinyals et al., Google, 2014)
- Têtes parlantes photo-réalistes en image de synthèse (Soong et Wang, Microsoft, 2014)
ST: Based on these accomplishments, we can easily project deep learning to impact many applications over the next decade. Some of the more impressive demonstrations of applied deep learning include the following:
- Automated image sharpening
- Automating image upscaling
- WaveNet: generating human speech that can imitate anyone’s voice
- WaveNet: generating believable classical music
- Speech reconstruction from silent video
- Generating fonts
- Image autofill for missing regions
- Automated image captioning (see also: https://github.com/karpathy/neuraltalk2)
- Turning hand-drawn doodles into stylized artwork
Tr: Suite à ces réussites, on peut aisément s’attendre à ce que le deep learning ait une influence sur de nombreuses applications dans la décennie à venir. Mais parmi les démonstrations les plus impressionnantes de l’utilisation du deep learning, on compte les suivantes :
- Amélioration automatisée de la netteté d’image
- Automatisation de l’upscaling d’image
- Réseau WaveNet : génération de parole humaine pouvant imiter toute sorte de voix
- Réseau WaveNet : génération de musique classique réaliste
- Reproduction de la parole à partir de vidéo muette
- Génération de police d’écriture
- Reconstitution automatique de zones d’images manquantes
- Sous-titrage d’image automatisé (à voir également : https://github.com/karpathy/neuraltalk2)
- Transformation de gribouillages en œuvre d’art stylisée
ST: We probably won’t realize all of the major commercial applications until they’re right in front of our faces. Understanding the advances in deep network architecture is important in order to understand application ideas going forward.
Tr: Si nous ne nous rendons pas compte immédiatement de toutes les applications réelles existantes, il est tout de même important de comprendre les progrès du deep learning afin d’en appréhender les futurs concepts.
ST: Advances in network architecture
rom multilayer feed-forward networks toward newer architectures like CNNs and Recurrent Neural Networks, the discipline saw changes in how layers were set up, how neurons were constructed, and how we connected layers. Network architectures evolved to take advantage of specific types of input data.
Tr: Progrès dans l’architecture réseau
Alors que la recherche faisait passer l’état de l’art des réseaux multi-couches à rétro-propagation aux architectures comme les RNC et les RNR, des changements apparurent dans la configuration des couches, la construction des neurones et la connexion entre couches. Les architectures réseau évoluèrent pour tirer profit de données d’entrée spécifiques.
ST: Advances in layer types.
Layers became more varied with the different types of architectures. Deep Belief Networks (DBNs) demonstrated success with using Restricted Boltzmann Machines (RBMs) as layers in pretraining to build features. CNNs used new and different types of activation functions in layers and changed how we connected layers (from fully connected to locally connected patches). Recurrent Neural Networks explored the use of connections that better modeled the time domain in timeseries data.
Tr: Progrès dans les types de couches
Des couches plus diversifiées avec des architectures de différents types furent créées. L’utilisation des machines de Boltzmann restreintes (Restricted Boltzmann Machines – RBM) comme couches de pré-entraînement pour la construction de caractéristiques par les réseaux de croyances profondes (Deep Belief Networks – DBN) a été une réussite. Les RNC utilisèrent de nouveaux types de fonctions d’activation dans les couches et modifièrent la manière de les connecter (de connexions totales à des connexions locales de grappes). Les réseaux de neurones récurrents explorèrent l’utilisation de connexions permettant de mieux modéliser le domaine temporel dans les séries de données temporelles.
ST: Advances in neuron types.
Recurrent Neural Networks specifically created advancements in the types of neurons (or units) applied in the work around LSTM networks. They introduced new units specific to Recurrent Neural Networks such as the LSTM Memory Cell and Gated Recurrent Units (GRUs).
Tr: Progrès dans les types de neurones
Les réseaux de neurones récurrents amenèrent des améliorations dans les types de neurones, ou unités, utilisés dans les travaux liés aux réseaux LSTM. Ils lancèrent des unités nouvelles qui leur étaient propres, comme la cellule de mémoire des réseaux LSTM et réseaux récurrents à portes (Gated Recurrent Units ou GRU).
ST: Hybrid architectures.
Continuing the theme of matching input data to architecture type, we have seen hybrid architectures emerge for types of data that has both a time domain and image data involved. For instance, classifying objects in video has been successfully demonstrated by combining layers from both CNNs and Recurrent Neural Networks into a single hybrid network. Hybrid neural network architectures can allow us to take advantage of the best of both worlds in some cases.
Tr: Architectures hybrides
Poursuivons dans l’idée de faire correspondre les données d’entrée au type d’architecture. Des architectures hybrides sont apparues, dont les données présentent à la fois un domaine temporel et des données d’image. Par exemple, il a été démontré avec succès que la combinaison des couches de réseaux RNC et RNR en un réseau hybride unique permet de répertorier des objets dans les vidéos. Dans certains cas, il est donc possible d’utiliser les architectures de réseaux de neurones hybrides afin de profiter du meilleur des deux réseaux.
ST: From feature engineering to automated feature learning
Although deep networks might have innovated with new units and layers for their internals, they are still fundamentally capped with a discriminatory classifier at the end with the constructed features as input. Automating feature extraction is a common theme among the various architectures. Each architecture does feature construction differently and is specialized such that it is better at certain types of input than others. Yann LeCun hit on this theme describing deep learning when he said it was: “machines that learn to represent the world.”
Geoffrey Hinton talks about this theme in DBNs when he explains how RBMs are used to decompose the data into higher-order features.
Tr: De l’ingénierie des caractéristiques à l’apprentissage automatique des caractéristiques
Les réseaux profonds ont peut-être innové avec des unités et des couches d’un nouveau type pour leur fonctionnement interne, mais ils sont encore intrinsèquement limités par l’usage d’un classificateur discriminant avec comme données d’entrée des caractéristiques construites. Le sujet commun entre les différentes architectures est l’automatisation de la reconnaissance de caractéristiques. Chaque architecture a sa propre méthode pour construire les caractéristiques, cette méthode convient particulièrement à certaines données d’entrée mais moins à d’autres. Yann Le Cun aborda la description du deep learning comme des « machines qui apprennent à décrire le monde ».
Geoffrey Hinton évoque ce thème dans les réseaux de croyances profondes (DBN) lorsqu’il explique comment les machines de Boltzmann restreintes (RBM) permettent de décomposer les données en caractéristiques d’ordre supérieur.
ST: Categorizing DBNs
For the purposes of this book, we place DBNs (and autoencoders) in the UPN group of deep networks.
Staying with the image classification theme, we can use the example of face detection. Raw image data of faces as input have issues with how the face is oriented, lighting of the photo, and position of the key features of the face. The key features we’d normally associate with a face are things like the edge of the face, edges of specific features like eyes and nose, and then subtle features we don’t consistently see like dimples.
Tr: Catégorisation des DBN
Pour les besoins de cet ouvrage, nous considérons les DBN (et les auto-encodeurs) comme faisant partie du groupe des réseaux profonds pré-entraînés non supervisés (UPN pour Unsupervised Pretrained Networks).
Toujours sur le thème de la classification d’image, examinons l’exemple de la détection de visage. Les données d’entrée sont donc les images de visages brutes, dont les spécificités sont entre autres l’orientation du visage, l’éclairage de la photographie et l’emplacement des principaux traits du visage. Ces traits que l’on associerait naturellement à un visage sont par exemple les contours du visage, des yeux et du nez, puis les caractéristiques subtiles que l’on ne voit pas toujours, comme les fossettes.
ST: Feature engineering.
Handcrafting features has been a hallmark of machine learning for a long time. Practitioners who win competitions in machine learning often study the dataset thoroughly and use many arcane tricks to make the learning process as simple as possible for their learning algorithm. These datasets are often columnar/tabular text data and we can apply domain knowledge to specific columns so feature creation is more direct.
Tr: Ingénierie des caractéristiques ou « feature engineering »
La saisie manuelle de caractéristiques a été pendant longtemps un emblème du machine learning. Les professionnels vainqueurs de compétitions en machine learning étudient méticuleusement les ensembles de données et utilisent des stratagèmes obscurs afin de simplifier au maximum le processus d’apprentissage pour leur algorithme. Ces données sont souvent présentées sous forme de texte en colonne ou en tableau, rendant possible l’association d’un thème à des colonnes spécifiques et la création de caractéristiques plus directe.
ST: If we think back to Chapter 1 and how we modeled the input data as the A matrix in the equation Ax = b, we can see how we had to hand-code the values from the data into those specific columns of A. These handcrafted features tend to produce highly accurate models but take a lot of time and experience to produce. From a knowledge representation perspective, it’s like reading a poorly written book versus a book that is well-written and easy to read. The former takes us a lot longer to read and we need to spend more energy to get the same out of it as the latter.
Tr: Nous avons vu au chapitre 1 la modélisation des données d’entrée en tant que matrice A dans l’équation Ax = b, et qu’un encodage manuel des valeurs de ces données dans les colonnes spécifiques de A était nécessaire. Ces caractéristiques saisies à la main facilitent l’élaboration de modèles extrêmement précis mais requièrent énormément de temps et d’expérience. Pour comparer cela à un autre domaine du savoir, cela revient à comparer un livre mal rédigé à un livre très bien rédigé et agréable à lire. Le premier nous demande plus de temps et d’énergie à lire et à apprécier que ce dernier.
ST: Image classification is an interesting example because handcrafting image features is more difficult than creating features for tabular data. The information in images is not constrained to stay in the same column and can be influenced by lighting, angle, and other issues. Feature extraction and creation for images needed a new approach, which in some part drove the evolution of CNNs.
Tr: La classification d’images est un exemple particulièrement intéressant car saisir les caractéristiques d’images à la main est bien plus difficile que de créer des caractéristiques pour des tableaux de données. L’information contenue dans les images n’est pas destinée à être cantonnée dans une seule colonne mais peut être affectée par d’autres paramètres comme l’éclairage, l’angle etc. Une nouvelle approche de la reconnaissance et de la création de caractéristiques d’images était nécessaire, ce qui a en partie entraîné l’évolution des réseaux de neurones convolutifs.
ST: Feature learning.
Coming back to our face-detection example, a nose can be located in any set of pixels in an image as opposed to our bank balance always being located in a specific column in tabular data. With CNNs, we train the network to understand the edge of the nose and then the general shape of the nose from lower-level “noseedge” features. The first layers in the network might pick up those nose-edge features and then pass them on to later layers in the network as larger feature maps.
Tr: Apprentissage des caractéristiques
Dans notre exemple de détection de visage, un nez peut être situé dans n’importe quel ensemble de pixels de l’image, contrairement à notre solde bancaire qui sera bien classé dans une colonne d’un tableau de données. Avec les RNC, le réseau est entraîné à « comprendre » les éléments comme les contours du nez, puis la forme générale du nez, à partir de caractéristiques basiques propres à la description d’un nez. Les premières couches du réseau pourront prélever ces caractéristiques propres pour les transmettre ensuite aux couches suivantes du réseau en tant que cartes de caractéristiques plus complètes.
ST: These more granular patches of feature maps eventually are combined into a “face” feature at the latter layers of the CNN. This allows a CNN to take on a task that has been attempted many times before (“Is this a face?”) yet pose the question in a simpler way that takes less energy to answer in a more accurate way.
Tr: Ces cartes de caractéristiques à la granularité plus élevée sont enfin combinées pour donner une caractéristique de visage dans les dernières couches du RNC. Le RNC peut ainsi exécuter une tâche qui a déjà été tentée de nombreuses fois auparavant (la question « est-ce qu’il s’agit d’un visage ? ») tout en parvenant à poser la question originale de façon plus efficace, en obtenant une réponse plus précise et moins coûteuse
ST: Automated Feature Learning with Complex Data
Taking complex raw data and creating higher-order features automatically in order to make a simpler classification (or regression) output is a hallmark of deep learning.
As you progress through this book, you’ll get a better sense of how to match input data types to deep network architectures and how to set up these architectures to best model the underlying dataset.
Tr: Apprentissage automatisé des caractéristiques avec données complexes
La devise du deep learning est la suivante : utiliser des données brutes complexes pour créer des caractéristiques d’ordre supérieur de façon automatique, afin d’obtenir un résultat plus simple de classification (ou régression).
En avançant dans cet ouvrage, vous verrez plus aisément quand tel type de données d’entrée correspond à telle architecture de réseau profond, et comment configurer ces architectures afin qu’elles modélisent aux mieux l’ensemble de données sous-jacent.
ST: Generative modeling
Generative modeling is not a new concept, but the level to which deep networks have taken it has begun to rival human creativity. From generating art to generating music to even writing beer reviews, we see deep learning applied in creative ways every day. Recent variants of generative modeling to note include the following:
- Inceptionism
- Modeling artistic style
- Generative Adversarial Networks
- Recurrent Neural Networks
Let’s quickly review each of these.
Tr: Élaboration d’un modèle génératif
Le concept d’élaboration d’un modèle génératif (generative modeling) n’est pas nouveau, mais le niveau auquel l’ont placé les réseaux profonds rivalise déjà avec la créativité humaine. Nous voyons quotidiennement la créativité du deep learning dans des réalisations comme la génération d’œuvres artistiques, de musique, et même la rédaction de critiques sur les bières ! Parmi les variantes récentes notables du generative modeling, on compte :
- L’« inceptionnisme » (images générées par des réseaux neuronaux)
- La modélisation artistique
- Les Generative Adversarial Networks ou GAN (réseaux antagonistes génératifs)
- Les Réseaux de Neurones Récurrents
Analysons ces concepts rapidement.
ST: Inceptionism.
Inceptionism is a technique in which a trained convolutional network is taken with its layers in reverse order and given an input image coupled with a prior constraint. The images are modified iteratively to enhance the output in a manner that could be described as “hallucinative.” In examples for which the input involves images of the sky, we might see fish faces appear in clouds of the output image. This line of research from Google has shown discriminatory neural network models contain considerable information to generate images.
Tr: Inceptionnisme
L’inceptionnisme est une technique qui utilise un réseau convolutif entraîné et ses couches dans un ordre inversé, auquel on donne une image d’entrée associée à une contrainte préalable. Les images sont modifiées de manière itérative afin d’améliorer le résultat en sortie que l’on pourrait qualifier d’« hallucinant ». Par exemple avec des images de ciel en entrée, on pourrait ainsi découvrir des têtes de poissons flotter dans les nuages sur l’image en sortie. Dans cet axe de recherche, Google a montré que les modèles de réseaux de neurones discriminants contiennent un nombre considérable d’informations permettant de générer des images.
ST: Modeling artistic style.
learn the style of specific painters and then generate a new image in this style of arbitrary photographs. Figure 2-2 (which you saw earlier in Chapter 1) shows the amazing results. Imagine having your family photo painted by Vincent van Gogh. (By the time this book is published, this will probably be a Snapchat filter, so you won’t have to wait that long.)
Tr: Modélisation du style artistique
Certaines variantes de réseaux convolutifs ont démontré qu’elles étaient capables d’étudier le style de peintres donnés et de générer une nouvelle image à partir d’une photographie quelconque dans le style du peintre. L’illustration 2-2, déjà vue dans le chapitre 1, montre ces résultats étonnants. Que diriez-vous d’avoir votre photo de famille peinte par Vincent van Gogh ? (Le filtre Snapchat existera déjà certainement avant que ce livre soit publié, l’attente ne sera pas si longue !)
ST:

Figure 2-2. Stylized images by Gatys et al., 2015
In 2015, Gatys et al. published a paper titled “A Neural Algorithm of Artistic Style” in which they separate the style and the content of a painting. The CNN extracts the artist’s style into the network’s parameters, which can later be applied to arbitrary images to be rendered in the same style.
Tr: Illustration 2-2, Images stylisées par Gatys et al., 2015
Leon Gatys et ses collaborateurs publièrent en 2015 une étude intitulée « A Neural Algorithm of Artistic Style », dans laquelle le style et le contenu d’une peinture sont clairement séparés. Le RNC extrait les informations sur le style de l’artiste et les réinjecte dans les paramètres du réseau. Ces paramètres sont ensuite appliqués à des images prises au hasard afin de leur donner le même style.
ST: GANs.
The generative visual output of a GAN can best be described as synthesizing novel images by modeling the distributions of input data seen by the network. We cover GANs in more depth in Chapter 4.
Tr: Les GAN
Le résultat en image généré par un GAN peut être décrit comme des images de synthèse créées en modélisant les distributions de données d’entrée vues par le réseau. Les GAN seront abordés plus amplement dans le chapitre 4.
ST: Recurrent Neural Networks.
Recurrent Neural Networks have been shown to model sequences of characters and generate new sequences that are lucidly coherent. In Chapter 5, we take a look at an example of Recurrent Neural Networks in which we generate new lines of Shakespeare by modeling all of Shakespeare’s other works.
Tr: Les Réseaux de Neurones Récurrents
Il a été démontré que les réseaux de neurones récurrents peuvent modéliser des séquences de caractères et générer de nouvelles séquences clairement cohérentes. Nous étudierons un exemple de réseaux de neurones récurrents dans le chapitre 5, grâce auquel nous pouvons générer de nouvelles répliques de Shakespeare en modélisant l’ensemble de son œuvre.
ST: Another interesting application of Recurrent Neural Networks is the work by Lipton and Elkan in which the network models proper nouns like “Coors Light” and other aspects of beer jargon. The generated beer reviews can be guided with hints (e.g., “give me a 3-star review of a German lager”) and are impressive. Here’s a sample beer review generated by the program:
On tap at the brewpub. A nice dark red color with a nice head that left a lot of lace on the glass. Aroma is of raspberries and chocolate. Not much depth to speak of despite consisting of raspberries. The bourbon is pretty subtle as well. I really don’t know that find a flavor this beer tastes like. I would prefer a little more carbonization to come through. It’s pretty drinkable, but I wouldn’t mind if this beer was available.
Tr: On peut citer une autre application intéressante des réseaux récurrents, avec le travail de Z. C. Lipton et C. Elkan sur la modélisation de noms propres comme « Coors Light » par le réseau, et autres éléments du vocabulaire spécifique à la bière. Les évaluations générées sur les bières peuvent être orientées à l’aide d’indications (par ex. « propose-moi une évaluation sur 3 étoiles pour une bière blonde allemande ») et sont impressionnantes. Voici un exemple d’évaluation générée par le programme :
À la pression au pub. Une belle couleur rouge foncé avec une mousse agréable laissant une dentelle épaisse sur le verre. Avec des arômes de framboise et de chocolat. Rien d’exceptionnel à en dire en dehors de la persistance de l’arôme de framboise. L’arôme de bourbon est également assez subtil. Je n’arrive vraiment pas à définir le parfum de cette bière. Je la préférerais avec un peu plus de carbonatation. Elle est plutôt buvable, j’aimerais assez que cette bière soit disponible à l’achat.
ST: The Tao of deep learning
There is a lot of marketing noise and hype in the realm of deep learning today, some of it justifiably so. However, deep learning is still trying to answer the same fundamental machine learning questions like: “Is this image a face?” The difference is that deep learning has taken the previous generation’s neural network techniques and added advanced automated feature construction to make computationally difficult questions on complex data easier to answer.
Tr: Le Tao du deep learning
Le domaine du deep learning attire aujourd’hui un énorme engouement et beaucoup de marketing, parfois à raison. Pourtant, le deep learning essaie encore de répondre aux mêmes questions fondamentales du machine learning comme : « Est-ce que cette image représente un visage ? ». La différence réside dans le fait que le deep learning s’est servi des techniques des réseaux de neurones de la précédente génération auxquelles il a ajouté une méthode avancée de construction automatique de caractéristiques, afin de faciliter les réponses aux problématiques de calculs ardues sur les données complexes.
ST: When you use deep learning as a practitioner, the best way to take advantage of this power is to match the input data to the appropriate deep network architecture. If you do this, you can apply deep learning successfully in new and interesting ways. If you don’t, you won’t add any new modeling power beyond basic techniques like logistic regression. The remainder of this book is dedicated to giving you, as practitioner, the skills and context necessary to make these decisions and use deep learning well.
Tr: Vous souhaitez réussir avec le deep learning en l’appliquant d’une manière novatrice et passionnante ? En tant que professionnel, vous savez que vous devrez associer les données d’entrée à l’architecture de réseau profond la plus appropriée, si vous souhaitez tirer le meilleur de la puissance offerte par le deep learning. Sinon, vous ne serez pas en mesure d’apporter le moindre progrès dans la modélisation au-delà des techniques basiques comme la régression logistique. Le reste de cet ouvrage vous apportera, à vous professionnel, les compétences et le cadre nécessaires pour prendre les bonnes décisions et utiliser le deep learning à bon escient.
ST: Organization of This Chapter
In this chapter, we build on the concepts from Chapter 1 and dig further into specific architectures for deep networks. We’ll differentiate the architectures and break down how their components evolved differently, providing color on how this better extracts features from certain types of data. We close the chapter with some discussion of the practicality of deep learning and alleviate some misconceptions surrounding the domain today. With that, let’s continue our discussion of the architecture components relevant to deep networks.
Tr: Organisation du chapitre
Dans le présent chapitre, nous allons tirer parti des concepts vus dans le chapitre 1 et examiner les architectures spécifiques des réseaux profonds. Nous ferons ensuite une distinction entre les architectures et démontrerons que leurs composants n’ont pas évolué de la même façon et que ceci nuance la qualité de reconnaissance des caractéristiques selon le type de données. Pour clore ce chapitre, nous vous proposerons une réflexion sur l’utilité du deep learning et dissiperons quelques idées fausses sur ce domaine. Mais continuons notre réflexion sur les composants d’architecture applicables au deep learning.
ST: Common Architectural Principles of Deep Networks
Before we get into the specific architectures of the major deep networks, let’s extend our understanding of the core components. First, we’ll reexamine the core components again as follows and extend their coverage for the purposes of understanding deep networks:
- Parameters
- Layers
- Activation functions
- Loss functions
- Optimization methods
- Hyperparameters
Tr: Principes architecturaux communs aux réseaux profonds
Avant d’aborder les architectures spécifiques des réseaux profonds dominants, améliorons notre compréhension de leurs principaux composants. Nous allons d’abord réexaminer les composants suivants, puis expliquer leur rôle au sein des réseaux profonds :
- Paramètres
- Couches
- Fonctions d’activation
- Fonctions de perte
- Méthodes d’optimisation
- Hyperparamètres
ST: Next, we’ll take these concepts and build on them to better understand the building block networks of deep networks, such as the following:
- RBMs
- Autoencoders
We’ll then continue to build on these ideas by reviewing these specific deep network architectures:
- UPNs
- CNNs
- Recurrent neural networks
- Recursive neural networks
Tr: Ensuite, nous nous appuierons sur ces concepts pour mieux comprendre les réseaux de base qui constituent les réseaux profonds, comme par exemple :
- RBM
- Auto-encodeurs
Dans la continuité de ces concepts, nous examinerons également les architectures particulières suivantes :
- UPN
- Réseaux de neurones convolutifs
- Réseaux de neurones récurrents
- Réseaux de neurones récursifs
ST: As we work our way through this chapter, we’ll also drop references to how DL4J implements certain aspects of deep networks. For now, let’s continue our review of parameters to better understand how they are extended for deep networks.
Tr: À travers ce chapitre, nous ferons également mention de la manière dont DL4J (logiciel open-source « Deep Learning for Java ») adopte certains aspects des réseaux profonds. Mais commençons notre analyse des paramètres et de la façon dont ils sont transposés aux réseaux profonds.
ST: Parameters
We learned in Chapter 1 that parameters relate to the x parameter vector in the equation Ax = b in basic machine learning. Parameters in neural networks relate directly to the weights on the connections in the network. In Figure 1-4 (introduced first in Chapter 1) we can see the parameter vector represented by the x column vector. We take the dot product of the matrix A and the parameter vector x to get our current output column vector b. The closer our outcome vector b is to the actual values in the training data, the better our model is. We use methods of optimization such as gradient descent to find good values for the parameter vector to minimize loss across our training dataset.
Tr: Paramètres
Nous avons appris dans le chapitre 1 que les paramètres se rapportent au vecteur de paramètres x dans l’équation Ax = b en machine learning basique. Dans les réseaux de neurones, les paramètres se rapportent directement aux poids donnés aux connexions dans le réseau. Dans le tableau 1-4 (vu au chapitre 1), on constate que le vecteur de paramètres est représenté par le vecteur colonne x. Du produit de la matrice A et du vecteur de paramètres x résulte le vecteur colonne de sortie b. Plus le résultat du vecteur b est proche des valeurs réelles des données d’entraînement, meilleur est le modèle. Nous utilisons des méthodes d’optimisation comme la descente de gradient afin de trouver les bonnes valeurs du vecteur de paramètres qui minimisent les pertes à travers l’ensemble des données d’entraînement.
ST: In deep networks, we still have a parameter vector representing the connection in the network model we’re trying to optimize. The biggest change in deep networks with respect to parameters is how the layers are connected in the different architectures. In DBNs, we see two parallel sets of feed-forward connections with two separate networks. One network’s layers are composed of RBMs (subnetworks in their own right, which we’ll review later in the chapter) used to extract features for the other network. The other network in a DBN is a regular feed-forward multilayer neural network, which uses the features extracted from the RBMs–layer network to initialize its weights. This is just one example of many that we’ll see over the course of this chapter in how parameters/weights are specialized in different deep network architectures.
Tr: Dans les réseaux profonds, on retrouve également un vecteur de paramètres qui représente la connexion dans le modèle de réseau à optimiser. La grande différence relative aux paramètres dans les réseaux profonds, réside dans la manière dont les couches sont reliées entre elles dans les différentes architectures. Les DBN ont deux ensembles parallèles de connexions à rétro-propagation avec deux réseaux séparés. Les couches d’un de ces réseaux sont composées d’RBM, des sous-réseaux en soi que nous analyserons plus tard dans ce chapitre, chargés de la reconnaissance de caractéristiques pour l’autre réseau. Ce dernier est en fait un réseau classique multi-couches à rétro-propagation, qui utilise les caractéristiques venant du réseau de sous-couche RBM pour initialiser ses poids. Il s’agit ici d’un exemple parmi d’autres que nous verrons dans ce chapitre, de la façon dont les paramètres et poids sont spécialisés dans différentes architectures de réseaux profonds.
ST: Parameters and NDArrays
In terms of working with the core linear algebra of deep networks, DL4J relies on the ND4J library to represent these linear algebra primitives. NDArrays and linear algebra are key to working with neural networks in DL4J.
Tr: Paramètres et tableaux à N dimensions
Lorsqu’il est question d’algèbre linéaire basique pour des réseaux profonds, DL4J s’appuie sur la librairie ND4J (N-Dimensional Arrays for Java) pour représenter ces primitives d’algèbre linéaire. Dans DL4J, les tableaux à N dimensions et l’algèbre linéaire sont essentiels pour travailler avec des réseaux de neurones
ST: Layers
In Chapter 1, we learned how input, hidden, and output layers define feed-forward neural networks. In Chapter 2, we further expanded this architecture with more types of layers and discussed how they relate to specific architectures of deep networks. Layers also can be represented by subnetworks in certain architectures, as well. In the previous section, we used the example of DBNs having layers composed of RBMs.
Tr: Couches
Nous avons vu dans le chapitre 1 que les réseaux de neurones à rétro-propagation sont définis par différentes couches : couche d’entrée, cachée et de sortie. Dans le chapitre 2, nous avons étendu cette architecture avec des types de couches plus nombreux et abordé leur relation avec des architectures spécifiques de réseaux profonds. Dans certaines architectures, on peut également représenter les couches comme des sous-réseaux, de la même manière que les couches de DBN étaient composées de RBM dans l’exemple de la section précédente.
ST: Layers are a fundamental architectural unit in deep networks. In DL4J we customize a layer by changing the type of activation function it uses (or subnetwork type in the case of RBMs). We’ll also look at how you can use combinations of layers to achieve a goal (e.g., classification or regression). Finally, we’ll also explore how each type of layer requires different hyperparameters (specific to the architecture) to get our network to learn initially. Further hyperparameter tuning can then be beneficial through reducing overfitting.
Tr: Les couches sont des composantes architecturales essentielles dans les réseaux profonds. Dans DL4J, on configure une couche en modifiant le type de fonction d’activation qu’elle utilise (ou le type de sous-réseau pour les RBM). Nous verrons également comment utiliser des associations de couches pour atteindre un objectif (par ex. classification ou régression). Enfin, nous comprendrons pourquoi chaque type de couche nécessite différents hyperparamètres (selon l’architecture) avant que le réseau ne commence à apprendre. Un réglage fin de ces hyperparamètres peut par la suite s’avérer bénéfique en diminuant le surapprentissage.
ST: Activation Functions
In Chapter 1, we reviewed the basic activation functions used in feed-forward neural networks. In this chapter, we begin to illustrate how activation functions are used in specific architectures to drive feature extraction. The higher-order features learned from the data in deep networks are a nonlinear transform applied to the output of the previous layer. This allows the network to learn patterns in the data within a constrained space.
Tr: Fonctions d’activation
Nous avons étudié les fonctions d’activation basiques utilisées dans les réseaux de neurones à rétro-propagation dans le chapitre 1. Dans ce chapitre, nous commençons à illustrer l’utilisation des fonctions d’activation qui permettent la reconnaissance de caractéristiques, dans des architectures spécifiques. Les caractéristiques d’ordre supérieur issues des données de réseaux profonds constituent une transformation non linéaire appliquée au résultat de la couche précédente. Cela permet au réseau de reconnaître des motifs dans les données au sein d’un espace restreint.
Source: extrait du livre blanc « Deep Learning, A PRACTITIONER’S APPROACH », éditions O’REILLY
Leave a Reply
You must be logged in to post a comment.